Is There an Existing Tech that Can ‘Extract’ Images from the Human Brain?

A few videos emerged online showing how advanced technology allegedly has become that it can now read images from the human brain. One of the videos is from a popular YouTube channel, showing videos or moving images generated by AI based on brain signals.
Many of those who have seen the clips were awed and thrilled by the technical marvel. Some were terrified, though, over the possibility that it may now be possible not only to know someone’s thoughts but see what people visualize in their minds. But is real mind-reading really possible now? Get to know the technology behind the intriguing mind-reading video clips.
Cinematic mindscapes
Researchers from the National University of Singapore and The Chinese University of Hong Kong developed a way to reconstruct human vision based on brain activities detected by functional magnetic resonance imaging (fMRI). In their study, entitled “Cinematic Mindscapes: High-quality Video Reconstruction from Brain Activity,” the researchers proposed the idea of Mind-Video, which is a machine learning system capable of progressively learning spatiotemporal information based on data captured by fMRI.
Attempts to extract data from brain activity are not new. This blog recently featured a technology that converts thoughts to texts. However, the concept of Mind-Video is more advanced, as it aims to reconstruct not only static images from brain fMRI scans but depictions of continuous visual experiences. In other words, it can generate moving images or videos depicting what a person has in mind.
The researchers successfully demonstrated the ability to produce good quality videos (albeit with arbitrary framerates) approximating the imagery a person has in mind. They captured continuous fMRI data obtained from cerebral cortex activity through a series of techniques. They then used AI to interpret the data and generate images
The results have been impressive, with the researchers saying that their Mind-Video system achieved an average accuracy of 85% based on semantic classification and a score of 0.19 in the structural similarity index (SSIM). The researchers are saying that these numbers represent significant improvements over preceding similar technologies.
Also, Mind-Video is reportedly “biologically plausible and interpretable,” which means that its methods and outputs are compatible with established physiological processes. The system used to detect brain activity, encode the signals, and then decode the signals into images are based on already existing biotechnologies.

How Mind-Video works
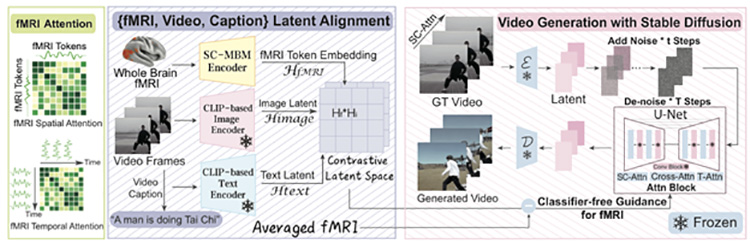
Mind-Video consists of two machine learning modules that connect the gap between image and video brain decoding. These modules are initially trained independently from each other, but they are eventually fine-tuned together.
In the first module, the system goes through progressive learning as it is fed with brain signal scans taken as a person views sets of images. In this part, Mind-Video establishes its comprehension of the semantic space, moving through multiple stages of learning.
The first part of the learning process in the first module makes use of unsupervised learning based on masked brain modeling to get accustomed to the general visual fMRI features. Multiple fMRI scans are processed in a sliding window. Features that are considered semantic-relevant are then distilled through the multimodality of the annotated dataset. In the process, the fMRI encoder is trained through contrastive learning.
The second module focuses on the fine-tuning of the learning of features. This module entails co-training with an augmented stable diffusion model particularly designed to generate videos based on the data compiled by the fMRI.
With this two-module system, the researchers were able to produce good quality videos with accurate semantics. The resulting images or videos demonstrated a good level of scene dynamics. The depiction of motion did not make the decoded images imperceptible, although there were some instances of obvious distortions.
Solid progress
Mind-Video builds on the outcomes achieved in the authors’ previous work, which was called Mind-Vis. This new system is a considerable improvement over its predecessor as it addresses the lack of pixel-level and semantic-level guidance in Mind-Vis.

The researchers compared Mind-Video’s output with those of previous work in fMRI video reconstruction, and they concluded with high level of confidence that Mind-Video’s methods produce moving images that are more semantically meaningful and closer to the reference image or ground truth.
This research imparts lessons that can guide other projects on fMRI data visualization. First, it shows that the visual cortex plays a vital role in the processing of visual spatiotemporal information, but higher cognitive networks like the dorsal attention network and default mode network can also help enhance the visual perception process.
Secondly, a layer-dependent hierarchy in the fMRI encoding process helps resolve more details in the output images. The first layers focus on structural details, while the succeeding ones tackle the more abstract visual features, resulting in better detail resolution.
Moreover, progressive semantic learning helps in fine-tuning the fMRI encoder as it improves stage by stage and is able to achieve better attention to higher cognitive networks. The progression allows the system to create more nuanced and semantically accurate images as Mind-Video keeps improving throughout the training stages.
More room for improvement
Mind-Video presents an exciting advancement when it comes to extracting data from the human mind. However, it still needs to go through more improvements to be considered a reliable solution for the extraction of images or videos from the human brain. It is still unable to depict exact forms and actions, let alone show human faces accurately based on someone’s memory. Mind-Video is indeed promising but its practical applications are quite limited given its current capabilities.